Автор статьи: Андрей Рогов
Введение
Задание номер 8 ЕГЭ по информатике — яркий пример случая, когда программное решение существует отдельно от аналитического, т. е. в них используются совершенно разные подходы. Про аналитический подход мы уже рассказали в другой статье. Теперь перейдём к программному.
Способы организации программы
Напомним основную концепцию задания: имеется некое множество объектов (обычно слова или числа), из которого необходимо выделить подмножество, обладающее определёнными признаками. Вычислительные мощности обычного компьютера позволяют перебрать все элементы множества и посчитать, сколько из них подходят под критерии. Для перебора элементов можно использовать два способа:
- Более простой для понимания — вложенные циклы. В заданиях встречаются четырёхбуквенные слова, пятизначные числа и т. п. Количество символов в слове или строке и будет определять, сколько циклов необходимо. Как правило, количество варьируется в пределах от 4 до 6
- Более простой для написания — функции модуля itertools. На самом деле, достаточно одной из них, product(), но в некоторых случаях её можно заменить permutations(). Далее расскажем об этих функциях подробнее
Общая структура программы выглядит так:
- Заводим необходимые счётчики (для количества подходящих слов или чисел, для нумерации)
- Организуем перебор всех комбинаций
- Проверяем, подходит ли под условие текущая комбинация
- Меняем значения счётчиков
- Выводим ответ
Модуль itertools
Встроенный в Python модуль itertools даёт доступ к итераторам, которые можно эффективно перебирать с помощью цикла. В модуле представлено множество итераторов, но на ЕГЭ обычно бывают полезны два: product() и permutations().
Product()
Официальная документация даёт довольно сложное определение этому итератору. Product() возвращает декартово произведение итерируемых объектов, подаваемых на вход. Другими словами, с помощью product() можно найти произведение множества X и множества Y. То есть это множество, содержащее все упорядоченные пары (x, y), в которых x принадлежит множеству X, а y принадлежит множеству Y.
Нам предстоит находить произведение множества само на себя. Чтобы вычислить произведение итерируемого объекта самого на себя, нужно указать количество повторений с помощью аргумента с ключевым словом repeat. Например, product(A, repeat=4) — то же самое, что и product(A, A, A, A).
Приведём несколько примеров использования этой функции.
a = '12'
b = '34'
list(product(a, b))
[('1', '3'), ('1', '4'), ('2', '3'), ('2', '4')]
# Каждому элементу строки a поставлен в пару каждый элемент строки b
a = '123'
list(product(a, a))
list(product(a, repeat=2))
[('1', '1'), ('1', '2'), ('1', '3'), ('2', '1'), ('2', '2'), ('2', '3'), ('3', '1'), ('3', '2'), ('3', '3')]
# Одинаковые результаты: каждому элементу строки сопоставляются все элементы этой строки
Обратите внимание, что для вывода на экран результат необходимо преобразовать в список. Элементами этого списка будут кортежи.
Permutations()
Представляет собой итератор, содержащий все возможные перестановки элементов.
list(permutations('12'))
[('1', '2'), ('2', '1')]
list(permutations('122'))
[('1', '2', '2'), ('1', '2', '2'), ('2', '1', '2'), ('2', '2', '1'), ('2', '1', '2'), ('2', '2', '1')]
list(permutations('1234', 3))
[('1', '2', '3'), ('1', '2', '4'), ('1', '3', '2'), ('1', '3', '4'), ('1', '4', '2'), ('1', '4', '3'), ('2', '1', '3'), ('2', '1', '4'), ('2', '3', '1'), ('2', '3', '4'), ('2', '4', '1'), ('2', '4', '3'), ('3', '1', '2'), ('3', '1', '4'), ('3', '2', '1'), ('3', '2', '4'), ('3', '4', '1'), ('3', '4', '2'), ('4', '1', '2'), ('4', '1', '3'), ('4', '2', '1'), ('4', '2', '3'), ('4', '3', '1'), ('4', '3', '2')]
Задача 1
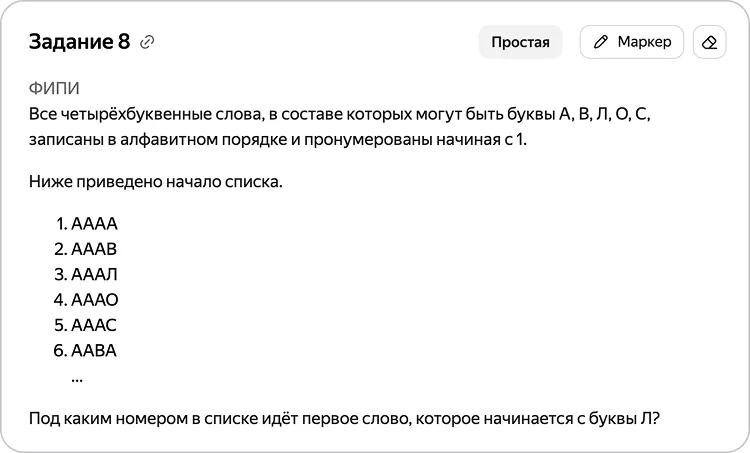
В первом варианте решения воспользуемся вложенными циклами. Для нумерации заведём отдельную переменную. Поскольку с помощью оператора break нельзя остановить все циклы, при нахождении первого подходящего слова используем команду exit().
n = 0 # нумерация списка
# буквы слов
for s1 in 'АВЛОС':
for s2 in 'АВЛОС':
for s3 in 'АВЛОС':
for s4 in 'АВЛОС':
n += 1
if s1 == 'Л': # если первая буква Л
print(n)# вывод номера слова
exit() # завершение программы
Вывод программы: 251.
Решим эту же задачу, но с помощью функции product().
from itertools import product
n = 0 # нумерация списка
# буквы слов
for s in product('АВЛОС', repeat=4):
n += 1
if s[0] == 'Л': # если первая буква Л
print(n)# вывод номера слова
break # завершение программы
Очевидно, что код стал короче и в нём нет вложенности многих уровней. Поскольку s — это кортеж, для обращения к первой букве используем индексацию.
Ответ: 251.
Задача 2

В этой задаче нет упорядоченного списка, поэтому не будем заводить отдельную переменную для подсчёта номера слова.
При переборе с помощью вложенных циклов каждая буква «лежит» в отдельной переменной. Чтобы проверить количество букв во всём слове, удобнее соединить все буквы в одну строку и, используя метод строк count(), узнать количество букв Б в ней.
k = 0 # счётчик подходящих слов
for s1 in 'БЕЛКА':
for s2 in 'БЕЛКА':
for s3 in 'БЕЛКА':
for s4 in 'БЕЛКА':
s = s1 + s2 + s3 + s4
if s.count('Б') == 1:
k += 1
print(k)
Вывод программы: 256.
Рассмотрим другой вариант решения: через библиотеку itertools.
from itertools import product
k = 0 # счётчик подходящих слов
for s in product('БЕЛКА', repeat=4):
if s.count('Б') == 1:
k += 1
print(k)
Следует внимательно следить за раскладкой клавиатуры! Программа пишется латиницей, а в словах используется кириллица, поэтому легко запутаться при переключении раскладки. При этом написание некоторых букв кириллицы совпадает с латинскими написаниями, например K. В этом случае можно не заметить, что в разных частях программы буквы набраны в разной раскладке (то есть разные буквы), хотя выглядят они одинаково.
Задача 3
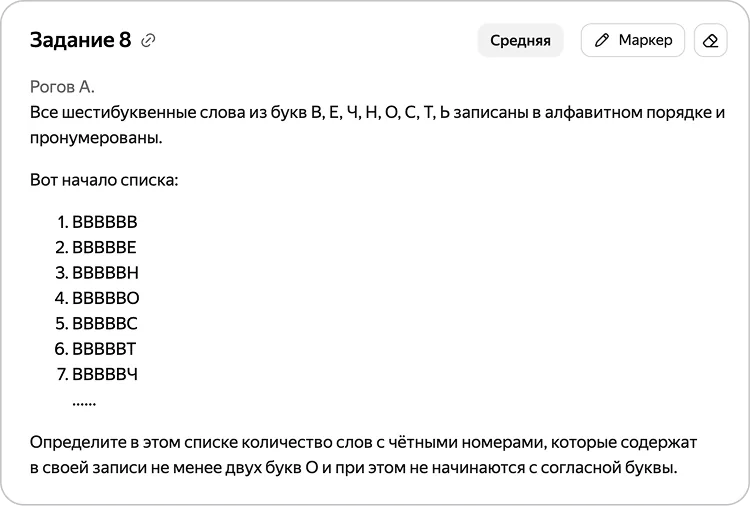
В этой задаче необходимо завести счётчики и для нумерации строк, и для количества слов. Важно перечислить буквы в алфавитном порядке.
k = 0 # счётчик подходящих слов
n = 0 # нумерация слов
for s1 in 'ВЕНОСТЧЬ':
for s2 in 'ВЕНОСТЧЬ':
for s3 in 'ВЕНОСТЧЬ':
for s4 in 'ВЕНОСТЧЬ':
for s5 in 'ВЕНОСТЧЬ':
for s6 in 'ВЕНОСТЧЬ':
n += 1
if n % 2 == 0:
s = s1 + s2 + s3 + s4 + s5 + s6
if s.count('О') >= 2:
if s1 not in 'ВНСТЧ':
k += 1
print(k)
Чтобы проверить, что слово не начинается с согласной, удобно использовать оператор in. Команда in проверяет, входит ли объект слева в объект справа. Поскольку слово не должно начинаться с согласной, используем конструкцию not in.
Вывод программы: 14 509.
Решение через itertools выглядит намного компактнее.
from itertools import product
k = 0 # счётчик подходящих слов
n = 0 # нумерация слов
for s in product('ВЕНОСТЧЬ', repeat=6):
n += 1
if n % 2 == 0:
if s.count('О') >= 2:
if s[0] not in 'ВНСТЧ':
k += 1
print(k)
Если вы знаете Python на более серьёзном уровне, можно упростить программу. Вместо ручной нумерации слов с отдельной переменной можно использовать функцию enumerate(), возвращающую два аргумента: номер и сам элемент. Указать начальное значение счётчика можно через именованный аргумент start. А чтобы упростить запись букв в алфавитном порядке, можно сортировать элементы строки. Функции product() будет не важно, строка на входе или список.
from itertools import product
k = 0 # счётчик подходящих слов
for n, s in enumerate(product(sorted('ВЕЧНОСТЬ'), repeat=6), start=1):
if n % 2 == 0:
if s.count('О') >= 2:
if s[0] not in 'ВНСТЧ':
k += 1
print(k)
Задача 4

Аналогично предыдущим задачам переберём все цифры числа. Чтобы учесть, что числа четырёхзначные, обязательно нужна проверка, что первая цифра не ноль. В случае вложенных циклов достаточно исключить ноль из первого цикла. Однако для задач с упорядоченным списком нельзя менять перебираемые строки. Поэтому более универсальное решение — делать отдельную проверку внутри циклов.
Проверить, что все цифры различны, можно попарным сравнением всех переменных, но это потребует шести операций сравнения. Удобнее использовать свойство множеств в Python. Элементы множества не могут повторяться, поэтому если в объекте все элементы различны, то при преобразовании во множество размеры объекта и множества будут одинаковы. Однако если в объекте были повторяющиеся элементы, то длина множества окажется меньше, поскольку повторяющиеся элементы будут исключены.
Проверить, что никакие две чётные или две нечётные цифры не стоят рядом, довольно сложно. Можно придумать много способов проверки, перебрать все неподходящие варианты или проверить чётность каждых соседних цифр. Мы поступим хитро. Заменим все чётные цифры 0, а нечётные — 1. В этом случае не подходящими под условие будут пары 00 и 11, которые легко проверить. Важно делать замены только после того, как мы убедились, что все цифры различны.
from itertools import product
k = 0 # счётчик подходящих чисел
for s1 in '0123456789':
for s2 in '0123456789':
for s3 in '0123456789':
for s4 in '0123456789':
if s1 != '0':
s = s1 + s2 + s3 + s4
if len(s) == len(set(s)):
s = s.replace('2', '0').replace('4', '0')
s = s.replace('6', '0').replace('8', '0')
s = s.replace('3', '1').replace('5', '1')
s = s.replace('7', '1').replace('9', '1')
if '00' not in s and '11' not in s:
k += 1
print(k)
Напишем решение с использованием модуля itertools.
from itertools import product
k = 0 # счётчик подходящих чисел
for s in product('0123456789', repeat=4):
if s[0] != '0':
s = ''.join(s)
if len(s) == len(set(s)):
s = s.replace('2', '0').replace('4', '0')
s = s.replace('6', '0').replace('8', '0')
s = s.replace('3', '1').replace('5', '1')
s = s.replace('7', '1').replace('9', '1')
if '00' not in s and '11' not in s:
k += 1
print(k)
Обратите внимание на новую строку s = ''.join(s). Поскольку s — кортеж, метод replace не будет работать. Нужно сначала преобразовать s в строку. Для этого необходим метод строк join, который соединит элементы s через разделитель, написанный перед точкой. В нашем случае это просто пустая строка.
Эту задачу можно также решить через permutations(). Тогда не нужно делать проверку, различны ли все элементы. Сама функция permutations() будет подразумевать, что из строки взяты разные цифры.
from itertools import permutations
k = 0 # счётчик подходящих чисел
for s in permutations('0123456789', 4):
if s[0] != '0':
s = ''.join(s)
s = s.replace('2', '0').replace('4', '0')
s = s.replace('6', '0').replace('8', '0')
s = s.replace('3', '1').replace('5', '1')
s = s.replace('7', '1').replace('9', '1')
if '00' not in s and '11' not in s:
k += 1
print(k)
Заключение
Мы рассмотрели методы программного решения задания номер 8 ЕГЭ по информатике. Программный метод решения — это эффективная альтернатива аналитическому подходу. Вложенные циклы хорошо подходят для простых случаев, а модуль itertools позволяет сократить объём кода.
Основные преимущества программного решения: автоматизация перебора всех возможных вариантов, возможность быстрой проверки сложных условий, минимизация риска ошибок, универсальность подхода для различных типов задач.
Таким образом, освоение программного решения задач на перебор комбинаций — это важный навык для успешной сдачи ЕГЭ по информатике и дальнейшего изучения программирования. Представленные методы и инструменты позволяют эффективно решать широкий спектр задач, связанных с перебором и анализом различных комбинаций.
Предлагаем решить подборку задач.